A3M: Adaptive, Adversarial and Multi-Objective Learning for Strategic Bidding in Repeated Auctions
arXiv:2606.28943v1 Announce Type: new Abstract: Learning to bid in repeated multi-unit auctions with bandit feedback poses a fundamental challenge. Existing methods often rely on rigid explore-then-exploit schedules, assume stationary adversaries, and optimize solely for bidder utility, thereby limiting adaptability and strategic robustness. To address these limitations, we introduce the A3M framework, which integrates adaptive deep reinforcement learning (DRL), explicit adversarial reasoning, a...
arXiv cs.CL
·Junhan Li, Yuxin Zhang, Haoran Wang, Minghao Chen
·
// relacionados

Leia também
Blog
Linq’s iMessage Apps Bring Payments, Tickets, Flights, and Games Into the iMessage Bubble Through the imessage_app Part
Blog
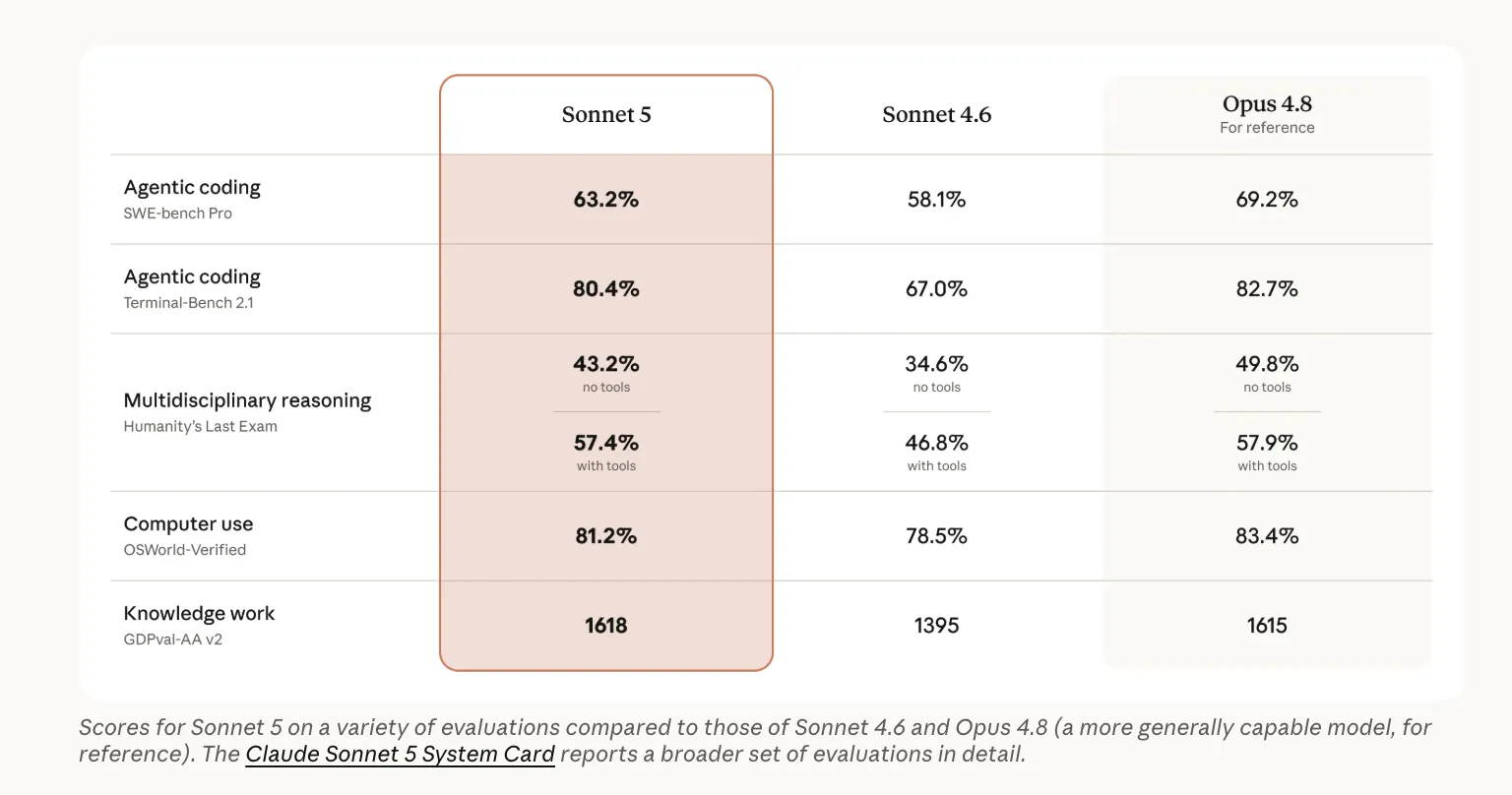
Anthropic Claude Sonnet 5 vs Sonnet 4.6 vs Opus 4.8: Agentic Coding Benchmarks, API Pricing, and Cost-Performance Tradeoffs Compared
Blog
Google's new Nano Banana 2 Lite image model is its fastest and cheapest yet
Blog